In the past few years, the term "microservice architecture" has been one of the most used buzzwords in the IT industry. The term was first used at an event for software architects in 2011, and soon people started to talk about it and tried to copy from some success stories about the early pioneers of it like Netflix and Amazon.
Philosophy behind microservices
It is usually difficult to maintain and scale large monolith applications that have been developed over time. A small change in one part of the code might break other parts of it because it is easy to introduce dependencies between parts of the code when boundaries are not strong. Also, writing tests in the codebase was usually considered "nice to have" and companies were avoiding them as much as possible, especially when traditional Agile software development processes were adopted. It is also not possible to scale only the specific parts of the system that need more resources. It is also more difficult to automate a large system because it takes a longer time and more resources to build and deploy a large system even if one small part of it has changed.
The microservice architecture was introduced to structure software solutions in a collection of small, independent, and loosely coupled services. These services can run in their own isolated process and communicate with other services through well-documented and consistent contracts using lightweight mechanisms, for example, HTTP resource APIs. These services can be written in different programming languages and can use different technologies for data storage. With this architecture, teams can independently work on different services, and the complexity of each service can be reduced, so we can build new features more often to keep managers happy! (oops! I mean business! 😅)
An architecture to solve all the problems?
It seems like finally we have a software architecture that can solve all the problems in this industry. It is something that some big players like Netflix and Amazon have successfully been using for years, so we should adopt it too, right?
Maybe not!
Let's take a look at the pros and cons of adopting this style of software architecture and see who can benefit from it and who should probably avoid it.
Pros
Independent development and deployment
Each service can be developed and deployed independently, so teams can work on different services in parallel. This can be a big advantage for companies that have a large number of technical staff and want to increase the speed of development. This can reduce the complexity of the process for them by reducing the number of needed inter-team communications.
Scalability
Each service can be scaled independently, so we can scale the services that are under heavy load and also reduce the cost of running the services that are not used that much.
Resilience
In an ideal world, when services can function without relying on the existence of the other ones, at the times when one service is down, most-likely other ones should still function. This can increase the total resiliency of the system.
Technology diversity
We can use different technologies for different services, so we can choose the best technology for each service. Even though theoretically it is possible to use a wide variety of technologies in each company, there is a debate on whether it is good or not. When too many programming languages and frameworks are used, It will become difficult to hire and efficiently distribute technical staff to work with different services. On the other hand, you will not put all your eggs (digital eggs 🥚) in one basket.
Cons
Complexity
The complexity of the system increases because we have more services to manage and more contracts to maintain. We might end up having different programming languages, different technologies for data storage, different processes, and different deployments.
Performance
The performance of the system can decrease especially if services synchronously call their downstream and wait for all the services involved in the request-handling chain to finish their process, store the updated state, and respond. We will also have the overhead of the network communication between services which is usually the slowest and most unreliable part of any IT solution.
Security
Having more dynamic nodes and processes in place means more items need to be secured. That means if we rely on traditional manual processes we might have no time left for more important things. That is why it is important to have one or more reliable security solutions in place to constantly analyze the code and infrastructure right from the beginning of the software development lifecycle.
Testing
Testing the system not only becomes more important but also becomes more complex, because we cannot assure the correctness of the system by just relying on simple sets of unit tests. We also need to test the integration between the services and if possible the system as a whole. It is also more important than ever to test for worst-case scenarios.
Deployment
Having more services means more deployment. That means if we continue using our manual processes, we will end up spending all our time on things that don't matter much for our business.
Monitoring and tracking
By using this architecture we will have more services and more instances of them to monitor. Now that the logic is distributed across multiple services and less-reliable network calls, we will have more points of failure to monitor.
Also, it is important to be able to trace the requests across all the services that are involved in handling requests to be able to debug the system when something goes wrong.
Debugging
Debugging the system becomes more complex because we have more services to debug and more contracts to maintain. In a monolith application, we can debug the whole system by looking at the logs in one stack, but in a microservice architecture at least we have to know what services are involved in handling different types of requests, then we should check what has gone wrong inside all the services involved in the failed action plus the communication layer between all the dynamic players.
Data consistency and data replication in a distributed environment
To have independent services, sometimes you need to replicate the same data in multiple databases. That means you have to build a mechanism to assure the data is always synced and consistent across all the services, otherwise might end up having different values for the same data in different services without even knowing what is the correct one.
No matter if SQL or NoSQL is used, it should be easier to achieve the C in ACID (Atomicity, Consistency, Isolation, and Durability) when dealing with traditional Local Transactions in a monolith. On the other hand, for Distributed Transactions two-phase commit (2PC) can be used, and for that you need a coordinator. This can cause unwanted locks on the row-level in tables. For Fragmented transactions, we can use the SAGA pattern to handle Long-Lived Transactions (LLT) with compensating action on all the involved services in case of a failure, so there should always be a "forward" and a "backward" scenario. This can be achieved either in an "orchestrated" fashion or "choreographed".
Ok, now you might think that you should use one shared database across all services instead because it might prevent this problem, but introducing such a bad dependency can exponentially increase the complexity!
Dealing with failure
In a monolith application, if one part of a chained related process fails, we can easily mark all the related actions as failed and roll back the database transaction in one go.
I will explain a similar situation with an example:
Think a customer opens the some-awesome-microservice-retail-webshop.com website and wants to order 500 of a new sort of light bulb. The "order service" checks the inventory for the availability of the product and allows the customer to place the order because 501 of that specific light bulb are available in the inventory. Then the customer attempts to pay and the order is placed when the payment is successful.
Then the system sends a confirmation email to the customer. So far everyone is happy!
A few seconds later, the inventory service is notified to reserve the newly-bought set of 500 light bulbs, but the request fails because meanwhile someone else has ordered 10 of the same product, so only 491 of the products are available. This one simple example shows that we have to consider dealing with scenarios where one part of the chained process fails. Shall we roll back the whole process? Shall we retry again? Are our services idempotent and can handle cases where a request is sent multiple times by mistake? Or business-wise the failed transaction should be dealt with in a different way? I talked about the solutions a bit in the previous bullet point.
In simple words, in the microservice architecture, we have to be prepared for the worse and be ready to handle unpredictable chaos, probably even by testing the resiliency of the system in a real live isolated environment.
What factors to consider?
Size of the team
While microservice architecture might help large organizations with 3+ teams of 4-8 developers, the overhead and complexity it adds can kill productivity in small companies.
In-house infrastructure knowledge
Microservices architecture tries to push a bit of the complexity from within the application to the infrastructure. That means you should adopt the culture of DevOps and your tech staff cannot be limited to developers only. You can either have a dedicated operations team to manage the infrastructure and mentor dev teams or you should hire one or two sysadmins either for each team or shared between a number of them.
Automation
Automation is the heart of the Microservice architecture, and without it, you will end up wasting your time manually performing all the time-consuming but similar provisioning tasks.
Visibility
Having hundreds of dynamically moving parts and heavily relying on a less-stable layer of network for the communication between services, it is crucial to have proper monitoring, logging, and tracing capabilities in place. That means, not only you should log the events in the application, but also you should log the network traffic between the services and the latency in responses to catch timeouts, etc.
Avoid service dependencies
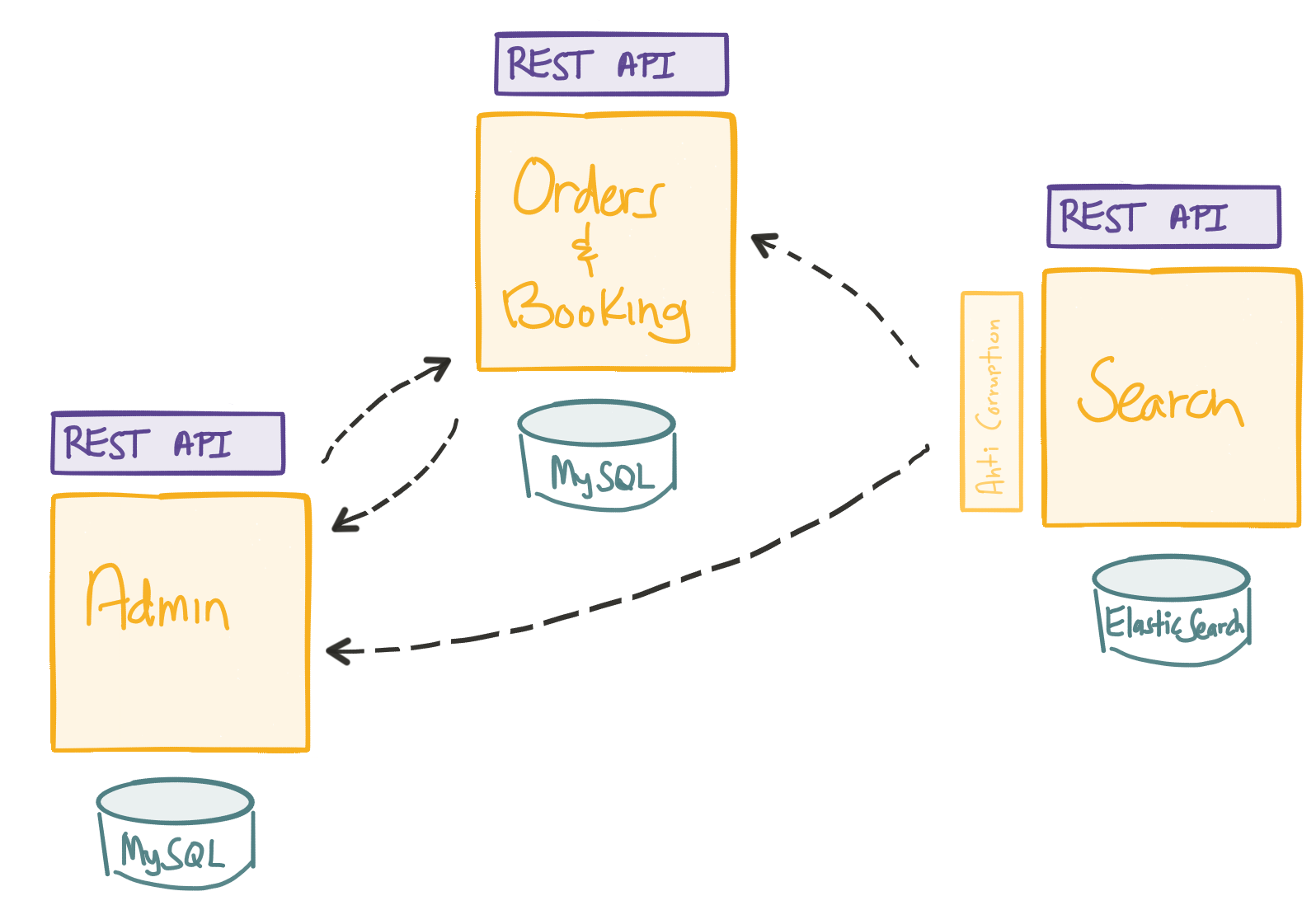
While this style of architecture is founded to put a hard line between services to decouple them from each other, I have seen cases where companies were using the same database for multiple services! This not only makes the database a single point of failure but also more importantly makes the functionality of services dependent on each other. This is one of the worst architectural decisions that can lead to building a "monolith microservice", most likely with 10x more complexity and maintenance issues.
You can also introduce dependency by using shared libraries and basically anything outside the context of the agreed contracts.
Mono-repo or isolated multi-repos?
Monorepo - Mono repo, mono build, isolated deployments. While having all the services in a single repository might be easier to maintain, it is too easy to reference the code from another service and break the decoupling between the services. Having everything in one codebase also means everything builds all together no matter what has changed in the code.
Semi-monorepo - Mono repo, isolated builds, isolated deployments. Similar to the previous one, this is also too easy to reference the code from another service, but unlike that, services are being built and deployed separately. The build logic will become complex.
Isolated repos - Isolated repos, isolated builds, isolated deployments. The boundary around services is harder so the independence factor will more likely be high unless you start using shared libraries and shared components which is an anti-pattern. The drawback is that you probably have to pull multiple repositories to make the solution work locally.
How services should communicate?
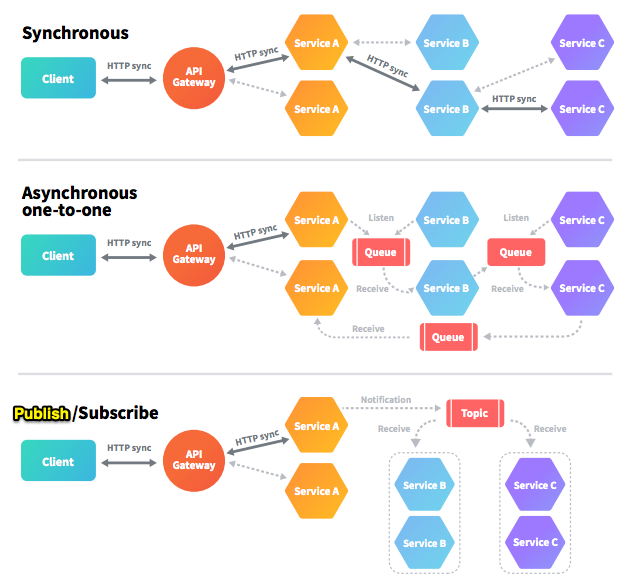
Even though it might be easier to synchronously call the downstream services, and go all the way through the chain of dependency, that can increase the response time of the customer's original request. This also increases the dependency between the services, and if one of the services is down, the whole chain will go to the weird state of being "half failed" and the original request might simply time out while half of the related changes are affected in our system.
To simplify the service-to-service communication, you might want to use the gateway pattern, where you have a single entry point for all the services to orchestrate how the request should be handled, but that becomes the single point of failure and can even become the bottleneck for the whole system. With this pattern, you can also simplify the authentication and authorization but that comes with the mentioned tradeoff.
To reduce the service dependency, you can use one of the asynchronous communication patterns. For example, the original request can be responded to immediately and the downstream service can process the message asynchronously. You can learn more about different styles of asynchronous communication here.
How to define the size of services?
You might be wondering how to define the right size for your services. Having too many services means having more communication over the network and more complexity in the orchestration of the system. That means services need to communicate to other services multiple times even for basic things so the dependency still is high but in another layer. On the other hand, having too few services means you still have smaller monoliths, and you will still have all the monolith issues, but of course on a smaller scale.
There is no "one answer" for every solution and every company of any size but these resources might help you make your decision more confidently:
- Martin Fowler's article on Microservices
- Bounded Context - Martin Fowler
- Using domain analysis to model microservices - Microsoft
- Event storming - Wikipedia
- Tips For Right-Sizing Microservices - Kristopher Sandoval
- What's the right size for a Microservice? - Kyle Gene Brown
Summary
While microservice architecture might help large organizations, the overhead and the complexity of it can kill productivity in small companies. Automation is the heart of the Microservice architecture, and you need to have proper monitoring, logging, and automated processes to assure the security of your system. There is no "one answer" for everyone to define the right size of services, but you can benefit from domain analysis and event storming to identify the bounded context and with the help of that you can define your services in a way that they won't need to communicate with each other too often.
